语音识别模型各部件数学原理
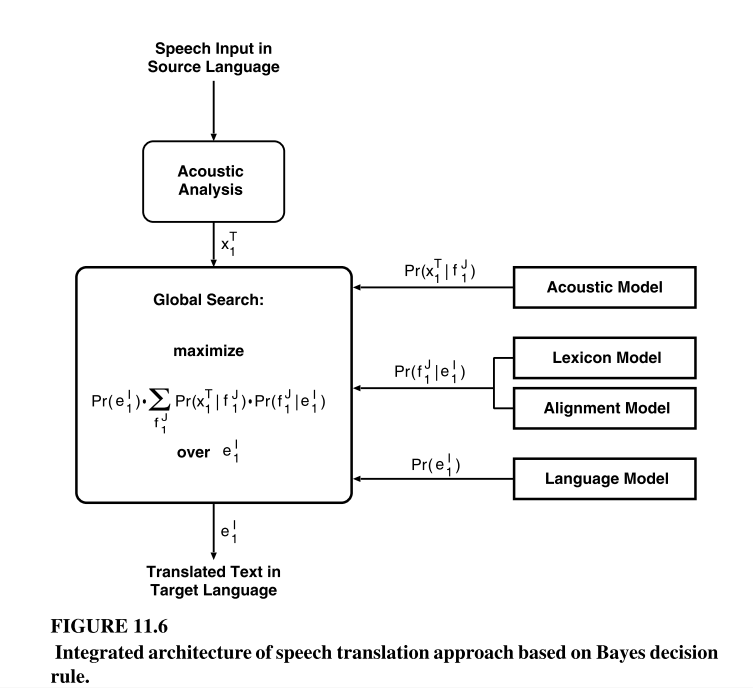
截自”C:\Users\tellw\open_title\papers\books- Pattern Recognition in Speech and Language Processing.pdf”第355页
这张图描述的是语音翻译的数学原理,从语音X到源语言F再到目标语言E的概率计算,找到最高概率的目标语言文字序列。
实际上语音识别——声学模型+语言模型的数学公式就是P(X|W)P(W),以中文语音识别为例,我们有一段中文语音,我们识别每一段文字音为一个拼音,做语音帧特征值到拼音的分类,找到最高P(X|W)的拼音序列,于是其他拼音序列的P(X|W)比这个拼音序列小,相同拼音序列的W的概率最大,语言模型找出最高存在概率的W使得整个式子概率最大。
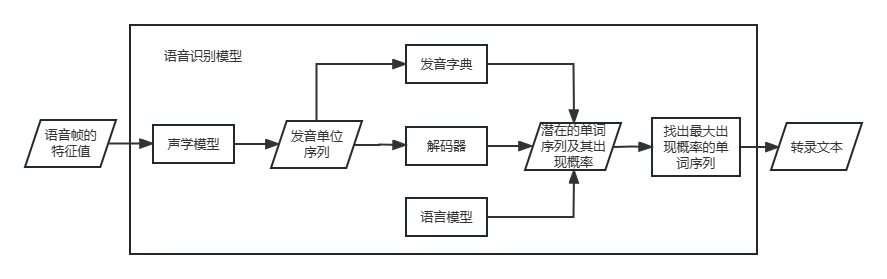
根据我的理解画的语音识别模型的各部件处理流程图。
贴一下大哥梳理的语音识别模型各部件的情况:
语音识别模型通常由以下几个部分组成:
前端处理器:将原始语音信号进行处理,提取出频域特征和时域特征,如MFCC特征和FBank特征等。
声学模型:根据前端处理器提取的特征,对语音进行建模,通常使用隐马尔可夫模型(HMM)或者深度神经网络(DNN)等模型进行建模。
语言模型:对识别结果进行优化,提高语音识别的准确率,通常使用n-gram语言模型或者神经网络语言模型进行建模。
解码器:根据声学模型和语言模型的得分,进行识别结果的解码,输出最终的识别文本。常用的解码器算法包括动态规划和束搜索等。
语音增强器:用于降噪和增强语音信号的质量,常用的方法包括谱减法、短时能量和短时平均幅度比等。
语音识别模型的部件这一概念来自启英泰伦文档中心 语音识别原理
大哥讲的训练语音识别模型的过程:
数据收集:收集大量的语音数据并对其进行标注,以便模型可以学习如何正确地识别语音。
特征提取:使用信号处理技术和机器学习算法从语音信号中提取特征,例如MFCC(Mel频率倒谱系数)。
模型选择:选择一个合适的模型来建立语音识别系统。常见的模型包括HMM(隐马尔可夫模型)和深度学习模型,如CNN(卷积神经网络)和RNN(循环神经网络)等。
训练模型:将数据输入到选择的模型中进行训练,并根据模型的输出进行调整和优化。
评估和测试:使用测试数据对模型进行评估和测试,并根据结果对模型进行改进,以提高其准确性。
创建于2023.3.21/12.27,修改于2023.4.7/12.45