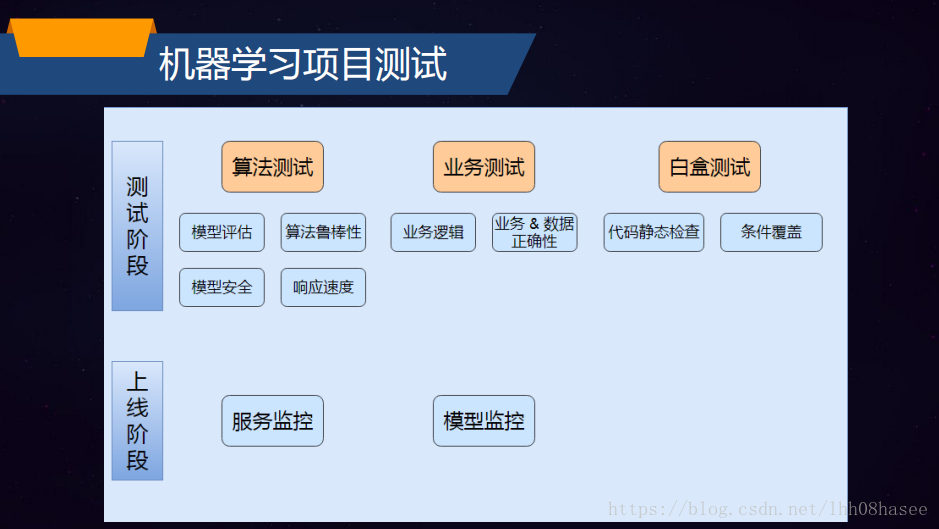
AI算法模型测试
模型评估
泛化能力指的是学习方法对未知数据的预测能力。就好比运动员平时都是在训练场进行训练,而评估运动员的真实实力要看在大赛中的表现。
我们实际希望的,是在新样本上能表现得很好的学习器,为了达到这个目的,应该从训练样本中尽可能推演出适用于所有潜在样本的 “普通规律”,这样才能在遇到新样本时做出正确的预测,泛化能力比较好。
当学习器把训练样本学得 “太好” 了的时候,很可能已经把训练样本自身的一些特点当作了所有潜在样本都会具有的一般性质,这样就会导致泛化性能下降。这种现象在机器学习中称为 “过拟合 “,与之相对是 “欠拟合” 指的是对训练样本的一般性质尚未学习。
有多种因素可能导致过拟合,其中最常见的情况是由于学习能力过于强大,以至于把训练样本所包含的不太一般的特性都学到了,而欠拟合则通常是由于学习能力低下而造成的。
衡量标准
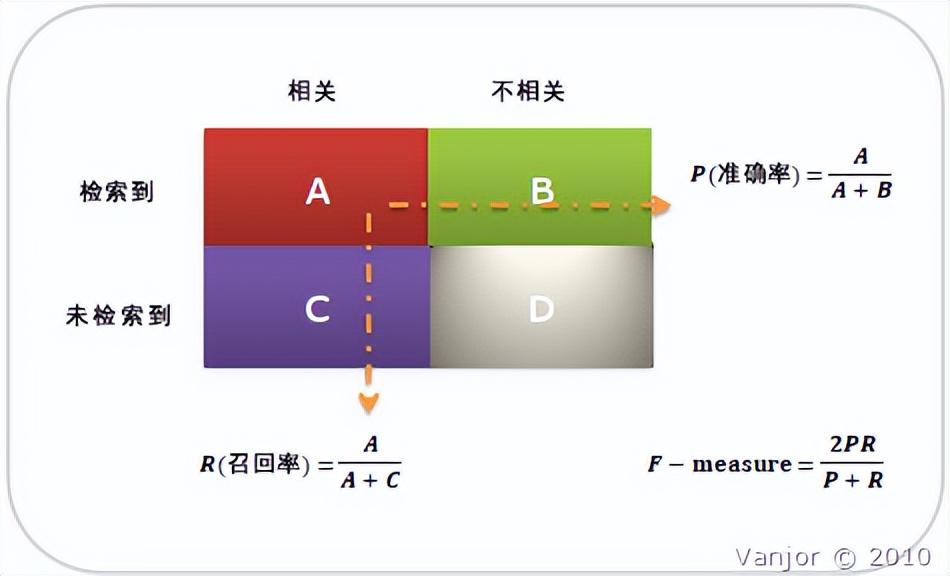
首先有关 TP、TN、FP、FN 的概念。大体来看,TP 与 TN 都是分对了情况,TP 是正类,TN 是负类。则推断出,FP 是把错的分成了对的,而 FN 则是把对的分成了错的。
【举例】一个班里有男女生,我们来进行分类,把女生看成正类,男生看成是负类。我们可以用混淆矩阵来描述 TP、TN、FP、FN。
混淆矩阵
| 相关(Relevant),正类 | 无关(NonRelevant),负类 | |
|---|---|---|
| 被检索到(Retrieved) | True Positives(TP,正类判定为正类,即女生是女生) | False Positives(FP,负类判定为正类,即“存伪”。男生判定为女生) |
| 未被检索到(Not Retrieved) | False Negatives(FN,正类判定为负类,即“去真”。女生判定为男生) | True Negatives(TN,负类判定为负类。即男生判定为男生) |
准确率、召回率、F1
人工智能领域两个最基本指标是召回率 (Recall Rate) 和准确率 (Precision Rate),召回率也叫查全率,准确率也叫查准率,概念公式:
◦召回率 (Recall) = 系统检索到的相关文件 / 系统所有相关的文件总数
◦准确率 (Precision) = 系统检索到的相关文件 / 系统所有检索到的文件总数
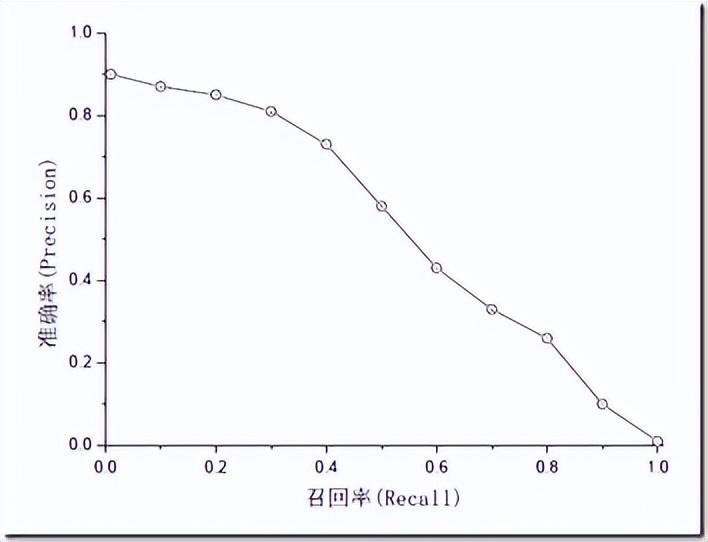
准确率和召回率是互相影响的,理想情况下肯定是做到两者都高,但是一般情况下准确率高、召回率就低,召回率低、准确率高,当然如果两者都低,那是什么地方出问题了。一般来说,精确度和召回率之间是矛盾的,这里引入 F1-Score 作为综合指标,就是为了平衡准确率和召回率的影响,较为全面地评价一个分类器。F1 是精确率和召回率的调和平均。F1-score 越大说明模型质量更高。一般情况,用不同的阀值,统计出一组不同阀值下的精确率和召回率,如下图:
评价指标跑出来看又怎么评判呢?我们来看下 2016 年的新闻
1 | 百度自动驾驶负责人王劲 2016 年 9 月 去年的这个时候,我们的图象识别,识别汽车这一项,刚好也是 89%。我们认为这个 89%,要达到 97% 的准确率,需要花的时间,会远远超过 5 年。而人类要实现无人驾驶,主要靠摄像头来实现安全的保障的话,我们认为要多少呢?我们认为起码这个安全性的保障,要达到 99.9999%,所以这个是一个非常非常远的一条路。我们认为不是 5 年,10 年能够达得到的。 一般的人工智能系统,如搜索、翻译等可允许犯错,而无人驾驶系统与生命相关,模型性能要求很高。 |
在不同的领域,对召回率和准确率的要求不一样。如果是做搜索,那就是保证召回的情况下提升准确率;如果做疾病监测、反垃圾,则是保准确率的条件下,提升召回。所以,在两者都要求高的情况下,可以用 F1 来衡量。
质量属性
鲁棒性(robustness),也就是所说健壮性,简单来说就是在模型在一些异常数据情况下是否也可以比较好的效果。也就是我们在最开始讲人工智能三个特征中的 处理不确定性的能力。
1 | 比如人脸识别,对于模糊的图片,人带眼镜,头发遮挡,光照不足等情况下的模型表现情况。 算法鲁棒性的要求简单来说就是 “好的时候” 要好,“坏的时候” 不能太坏。 在 AlphaGo 和李世石对决中,李世石是赢了一盘的。李世石九段下出了 “神之一手” Deepmind 团队透露:错误发生在第 79 手,但 AlphaGo 直到第 87 手才发觉,这期间它始终认为自己仍然领先。这里点出了一个关键问题:鲁棒性。人类犯错:水平从九段降到八段。机器犯错:水平从九段降到业余。 |
测试方法就是用尽可能多的异常数据来覆盖进行测试。
模型安全,攻击方法有:试探性攻击、对抗性攻击两种
在试探性攻击中,攻击者的目的通常是通过一定的方法窃取模型,或是通过某种手段恢复一部分训练机器学习模型所用的数据来推断用户的某些敏感信息。主要分为模型窃取和训练数据窃取
对抗性攻击对数据源进行细微修改,让人感知不到,但机器学习模型接受该数据后做出错误的判断。比如图中的雪山,原本的预测准确率为 94%,加上噪声图片后,就有 99.99% 的概率识别为了狗。
响应速度是指从数据输入到模型预测输出结果的所需的时间。对算法运行时间的评价。
业务测试,包括业务逻辑测试,业务 & 数据正确性测试。主要关注业务代码是否符合需求,逻辑是否正确,业务异常处理等情况。可以让产品经理提供业务的流程图,对整体业务流程有清晰的了解。
白盒测试,先让算法工程师将代码的逻辑给测试人员讲解,通过讲解理清思路。然后测试做代码静态检查,看是否会有基本的 bug。可以使用 pylint 工具来做代码分析。
模型监控,项目发布到线上后,模型在线上持续运行,需要以固定间隔检测项目模型的实时表现,可以是每隔半个月或者一个月,通过性能指标对模型进行评估。对各指标设置对应阀值,当低于阀值触发报警。如果模型随着数据的演化而性能下降,说明模型已经无法拟合当前的数据了,就需要用新数据训练得到新的模型。
大数据辅助,机器学习算法训练和验证是一个持续改进的过程。当数据量逐步放大时候,如何统计算法的准确率呢?这个时候需要引入大数据技术针对数据结果进行统计,根据周期性统计的准确率结果生成线性报表来反馈算法质量的变化。
备份自AI测试 AI 算法测试之浅谈第三小节
创建于2023.4.3/10.43,修改于2023.4.3/10.44