使用whisper
whisper是openAI开发贡献的开源语音识别库,git clone https://github.com/openai/whisper,pip install .,安装完whisper库。之后即可玩耍
whisper xxx.wav,使用small(461MB)模型识别多语种的语音。--language可指定目标语言,--task translate可规定额外执行翻译为英语的任务。指定--model为base格式和small格式,2GB的显存够用,small格式比base格式准确度更高。
对音频的采样率没有特别的要求,至于声道数有待验证
whisper xxx.mp4 --language Chinese --output_format srt
| 类型 | 参数数量 | 英语识别模型 | 多语言模型 | 要求的显存 | 相对速度 |
|---|---|---|---|---|---|
| tiny | 39M | tiny.en | tiny | ~1GB | ~32x |
| base | 74M | base.en | base | ~1GB | ~16x |
| small | 244M | small.en | small | ~2GB | ~6x |
| medium | 769M | medium.en | medium | ~5GB | ~2x |
| large | 1.55G | N/A | large | ~10GB | 1x |
whisper在各语种上的识别词错率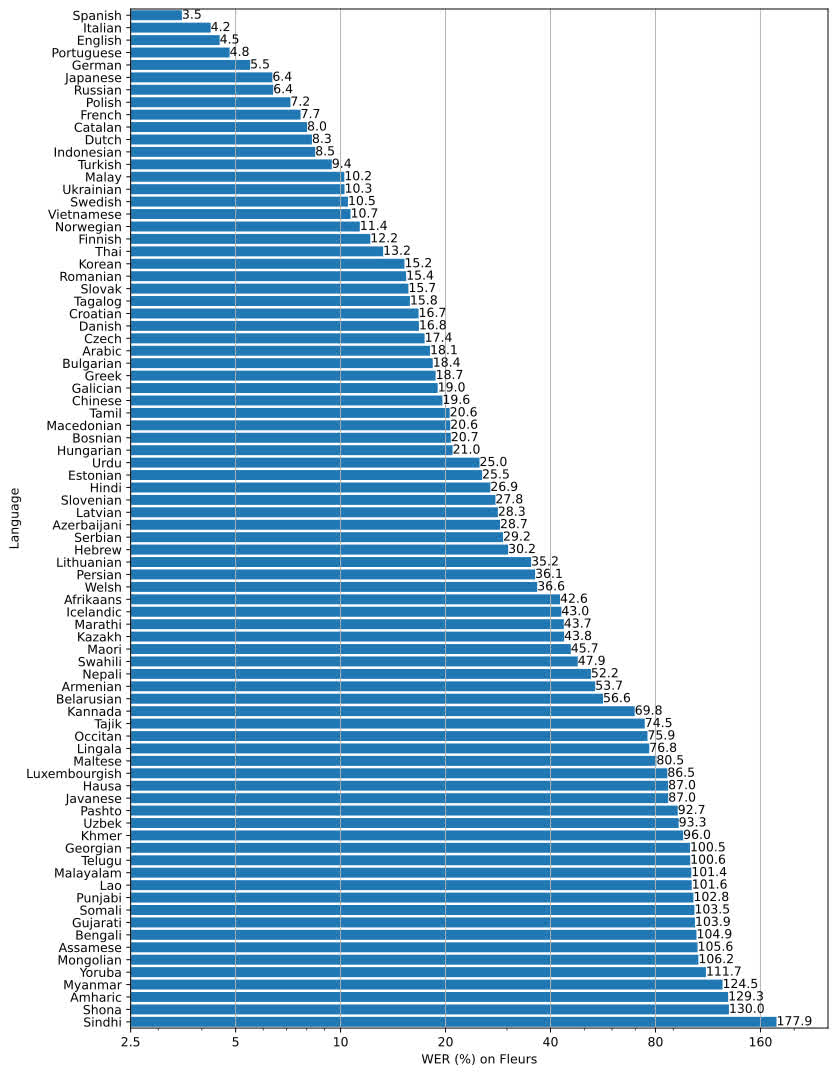
使用whisper做一个本地语音识别程序
import wave
import numpy as np
from pyaudio import PyAudio,paInt16
import time
import whisper
import os
import threading
recordingSaveDir='C:/Users/tellw/Music/records'
class recorder:
NUM_SAMPLES=2000
SAMPLING_RATE=8000
LEVEL=500
COUNT_NUM=20
SAVE_LENGTH=8
Voice_String=[]
pa=PyAudio()
stream=pa.open(format=paInt16,channels=1,rate=SAMPLING_RATE,input=True,frames_per_buffer=NUM_SAMPLES)
save_buffer=[]
recording=False
def savewav(self,filename):
wf=wave.open(os.path.join(recordingSaveDir,filename),'wb')
wf.setnchannels(1)
wf.setsampwidth(2)
wf.setframerate(self.SAMPLING_RATE)
wf.writeframes(np.array(self.save_buffer).tobytes())
wf.close()
def start(self):
threading._start_new_thread(self._record,())
def _record(self):
self.save_buffer=[]
save_count=20
self.recording=True
while self.recording:
string_audio_data=self.stream.read(self.NUM_SAMPLES)
audio_data=np.fromstring(string_audio_data,dtype=np.short)
large_sample_count=np.sum(audio_data>self.LEVEL)
if large_sample_count>self.COUNT_NUM:
save_count=self.SAVE_LENGTH
else:
save_count-=1
if save_count>0:
self.save_buffer.append(string_audio_data)
# print(self.save_buffer)
def end(self):
self.recording=False
if len(self.save_buffer)>0:
filename=f'{int(time.time()*1000)}.wav'
self.savewav(filename)
return filename
else:
print('record nothing')
return None
if __name__=='__main__':
r=recorder()
model=whisper.load_model('base')
while True:
command=input('i or o or q:')
if command=='q':
break
elif not r.recording:
print('recording...')
r.start()
elif r.recording:
filename=r.end()
if filename is not None:
result=model.transcribe(os.path.join(recordingSaveDir,filename))
print(result['text'])参考自通过pyaudio使用麦克风录音和用python编写录音机——GUI控制录音开始与结束(tkinter)
本文创建于2022.10.25/20.29,修改于2022.12.7/20.38